
免费同城空降app入口在哪

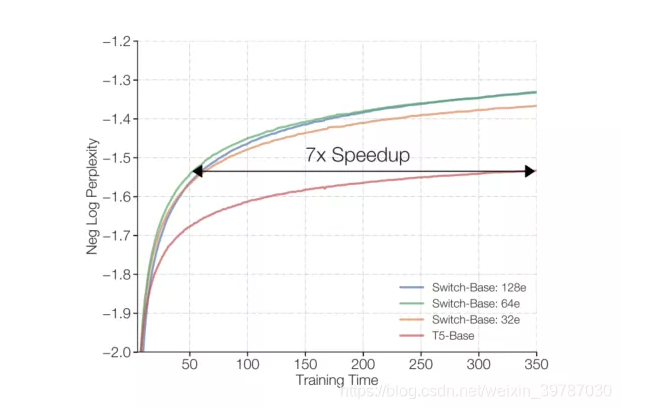
近日,Google Brain 团队在预印本发布论文《SWITCH TRANSFORMERS: SCALING TO TRILLION PARAMETER MODELS WITH SIMPLE AND EFFICIENT SPARSITY》,宣布利用万亿级参数进行预训练的稀疏模型 SWITCH TRANSFORMERS 的诞生,该方法可以在控制通信和计算资源的情况下提升训练的稳定性,同等计算资源条件下比 T5-XXL 模型快 4 倍。来自 Google Brain 的三位科学家 William Fedus、Barret Zoph 以及 Noam Shazeer 使用了 Switch Transformer 模型,简化了 MOE 的路由算法、设计了直观的改进模型,从而实现了通信和计算成本的降低。值得期待的是,这种训练方法修复了不稳定性,并且首次展示了大型稀疏模型在低精度(bfloat 16)格式下进行训练。将模型和 T5 模型进行对比,基于 101 种语言的设置和 C4 语料库(Colossal Clean Crawled Corpus,从网络上抓取的数百 GB 干净英语文本) 训练效果实现了对 T5 模型的超越,甚至是 7 倍速碾压。

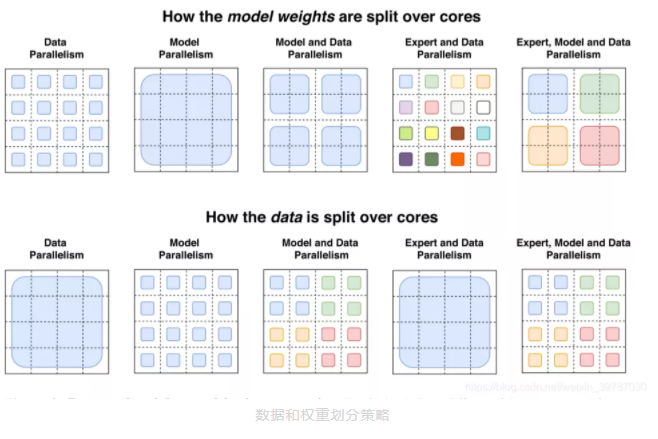
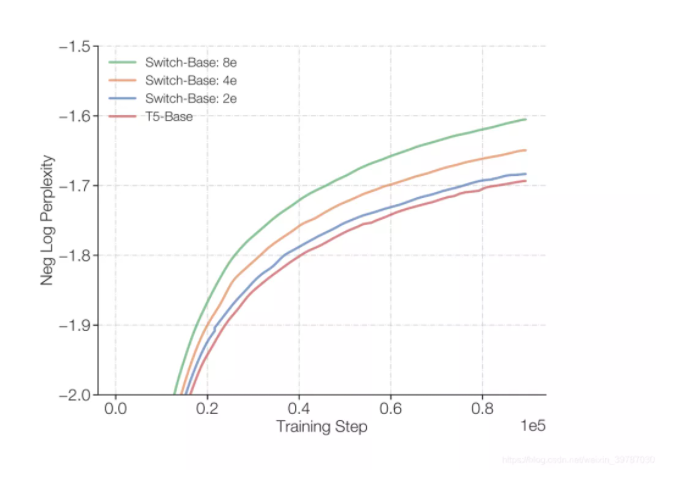
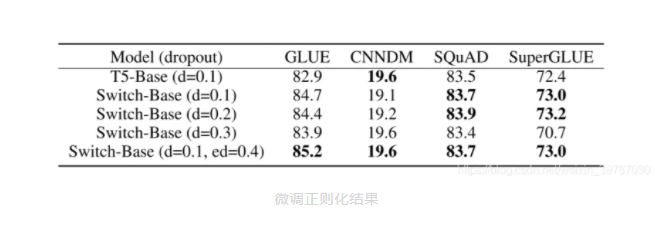
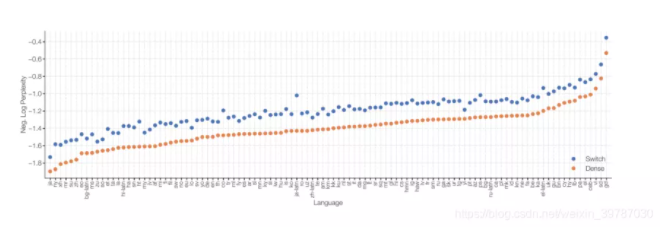
纯粹的参数技术会让 Switch Transformer 更好吗?
是的,看怎么设计!参数和总的 FLOPs 是独立衡量神经语言模型的标准。大型模型已经被证实具有良好的表现,不过基于相同计算资源的情况下,我们的模型具有更加简洁、有效且快速的特点。
我没有超算——模型对我来说依然有用吗?
虽然这项工作集中在大型模型上,我们发现只要有两个专家模型就能实现,模型需要的最低限制在附录当中有讲,所以这项技术在小规模环境当中也非常有用。
在速度-精度曲线上,稀疏模型相比稠密模型有优势吗?
当然,在各种不同规模的模型当中,稀疏模型的速度和每一步的表现均优于稠密模型。
我无法部署一个万亿参数的模型-我们可以缩小这些模型吗?
这个我们无法完全保证,但是通过 10 倍或者 100 倍蒸馏,可以使模型变成稠密模型,同时实现专家模型 30%的增益效果。
为什么使用 Switch Transformer 而不是模型并行密集模型?
从时间角度看,稀疏模型效果要优越很多,不过这里并不是非黑即白,我们可以在 Switch Transformer 使用模型并行,增加每个 token 的 FLOPs,但是这可能导致并行变慢。
为什么稀疏模型尚未广泛使用?
扩展密集模型的巨大成功减弱了人们使用稀疏模型的动力。此外,稀疏模型还面临一些问题,例如模型复杂性、训练难度和通信成本。不过,这些问题在 Switch Transformer 上也已经得到了有效的缓解。
参考资料:https://arxiv.org/pdf/2101.03961.pdf项目代码地址:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py


关键词:知识专区:1.6 万亿参数你怕了吗?谷歌大脑语言模型速度是 T5 速度的 7 倍,免费同城空降app入口在哪里_全国同城约会服务平台_同城快餐wx交流群_同城约茶服务网站,接私活,人到付款,同城服务,品茶,喝茶,过夜,酒店宾馆,qq,做完付款,新茶,微信.查询网上新闻,不限次数,00元,小时,约小姐,上门服务,小妹,100/200/300/400/500/6789,服务 ,喝茶工作室,可约可空降,快餐,联系电话,空降服务附近约茶,品茶,24小时,约会交友,附近喝茶,免费上门,上门服务,接单,小妹电话,上门卖身,个人接单上门服务,二维码,人到付款,微信,qq
 网站管理
网站管理