
免费同城空降app入口在哪
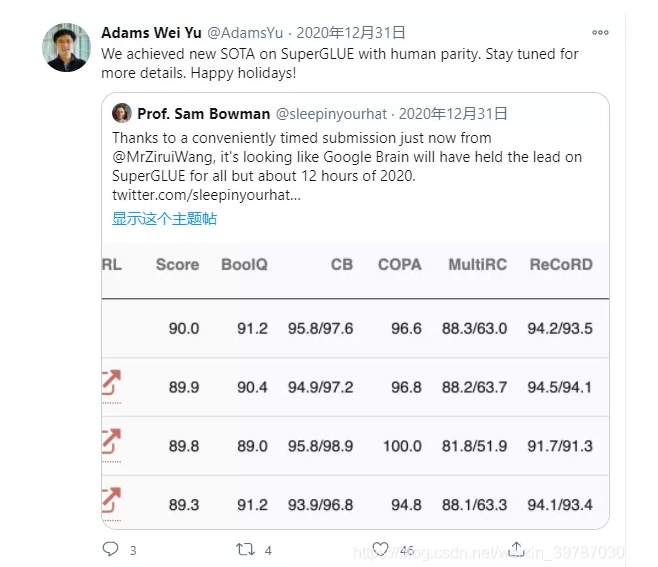
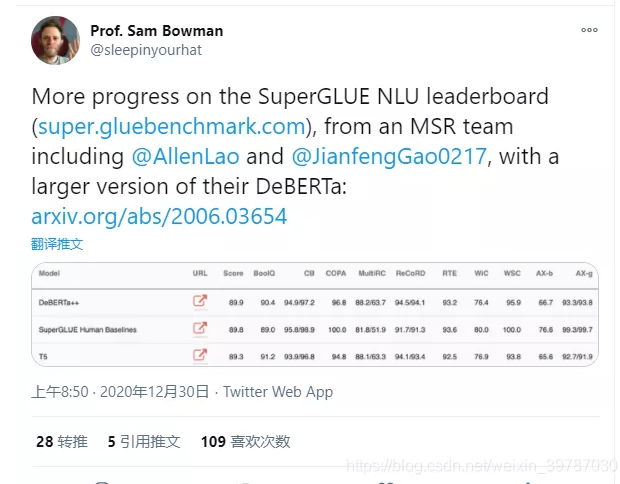
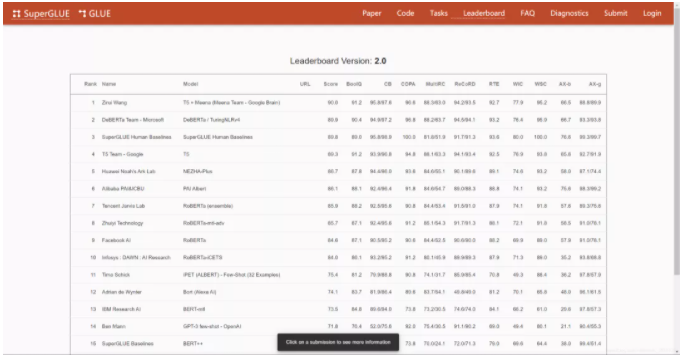
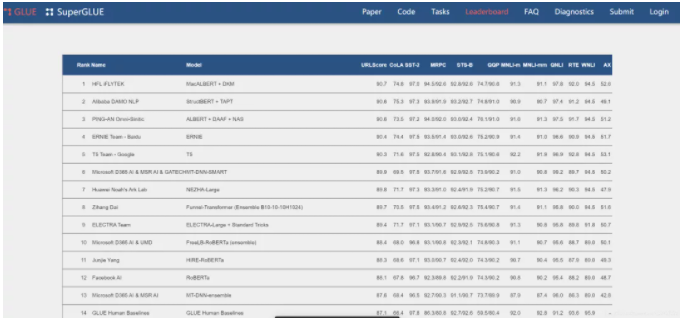



关键词:知识专区:谷歌大脑组合模型霸榜 SuperGLUE,免费同城空降app入口在哪里_全国同城约会服务平台_同城快餐wx交流群_同城约茶服务网站,接私活,人到付款,同城服务,品茶,喝茶,过夜,酒店宾馆,qq,做完付款,新茶,微信.查询网上新闻,不限次数,00元,小时,约小姐,上门服务,小妹,100/200/300/400/500/6789,服务 ,喝茶工作室,可约可空降,快餐,联系电话,空降服务附近约茶,品茶,24小时,约会交友,附近喝茶,免费上门,上门服务,接单,小妹电话,上门卖身,个人接单上门服务,二维码,人到付款,微信,qq
 网站管理
网站管理